
When was the last time you tried restoring your data from a backup? If the answer is “never,” you’re not alone – one survey found 33% of organizations admit they test their disaster recovery (DR) plan infrequently or never at all. Unfortunately, not testing your backups is like having a spare tire you’ve never inflated; you won’t know it’s flat until you’re stranded. Major incidents in recent years underscore this risk: for example, a Toyota plant suffered a 36-hour shutdown in 2023 due to recovery delays, and a company hit by ransomware needed over 72 hours to restore email systems from backups. These cases highlight why regularly conducting disaster-recovery drills – essentially “fire drills” for your IT systems – is crucial to ensure your backups actually work when it counts. In this guide, we’ll explain how to test your backups without causing downtime or damage to your production environment, so you can be confident your data is safe no matter what.

Why Regular Disaster Recovery Drills Matter
Backing up data is only half the battle – the other half is making sure those backups can be restored. It’s common for businesses (and individuals) to set up backup solutions and then assume everything will magically work in an emergency. In reality, backups can fail, become corrupted, or not meet your recovery needs. Here are some key reasons testing your backups regularly is so important:
- Data Integrity: Regular testing ensures your backed-up data is complete, accurate, and uncorrupted, so you won’t discover a faulty backup when you need it most. (You don’t want the first restore attempt during a crisis to reveal that the files were never backing up properly!)
- Recovery Process Validation: A drill lets you verify your recovery procedures work as intended on your current systems. You can check that you’re able to actually restore from your backups and that the restored systems function correctly and within acceptable time frames. This builds confidence that your disaster recovery plan will succeed when activated.
- Downtime Minimization: By testing backups, you can identify and fix issues in your backup-and-restore process before a real disaster hits. This proactive approach helps reduce downtime during an actual outage, keeping your business running more smoothly when every minute of downtime costs money.
- Staff Preparedness: Disaster recovery drills double as training exercises. Practicing restores prepares your team to handle real emergencies calmly and quickly. Think of it as a fire drill for your IT staff – everyone learns their role and gains confidence, so a crisis isn’t the first time they’re trying to perform a recovery.
- Compliance Requirements: Many industries (healthcare, finance, government, etc.) have strict regulations for data protection and continuity. Regular backup testing demonstrates compliance with these standards. It proves to auditors and stakeholders that you can actually restore critical data (e.g. patient records, financial info) if something goes wrong, reducing legal or regulatory risks.
- Adapting to Changes: IT environments don’t stand still – you add new systems, update software, and change infrastructure over time. Periodic drills ensure your backup strategy keeps up with these changes. For instance, if you migrate a server to the cloud or implement a new application, a recovery test will confirm that those are included in your backups and can be restored properly.
In short, a disaster-recovery drill is the only way to get real assurance that your backups will actually save the day. Even for a home user, it’s wise to occasionally test restoring a few files from your external drive or cloud backup – better to know now if there’s an issue than when you’re trying to recover precious family photos. As the saying goes, “a backup isn’t truly a backup until you’ve tried restoring it.”
In a study, 58% of companies said they test their DR plan only once a year or less, and 1 in 3 admitted they rarely or never test at all. It's no surprise that lack of testing is a major reason many businesses struggle to recover from outages. A minor IT hiccup can turn into a serious downtime nightmare if your backups haven’t been verified. Don’t let that be you – schedule regular drills as part of your business routine.
Real-World Insight

How to Test Your Backups Safely (Without Disrupting Operations)
You might be thinking, “Alright, testing backups is important – but how do I do it without breaking anything or shutting down my office?” The good news is that with careful planning, you can conduct disaster recovery drills in a safe, controlled way. Here’s a step-by-step approach:
1. Review Your Disaster Recovery Plan and Set Objectives. Start by revisiting your disaster recovery (DR) plan (or create one if you haven’t already). Identify your mission-critical systems and data, and clarify your recovery objectives. Two key terms to know are RTO (Recovery Time Objective) – the maximum acceptable downtime, and RPO (Recovery Point Objective) – the maximum acceptable data loss (how up-to-date your restored data should be). For example, an RTO of 4 hours means you need to be back up within 4 hours of an incident; an RPO of 1 hour means you can only afford to lose at most 1 hour of data. Define these targets for your business. Also, make sure roles and responsibilities are assigned – who on your team (or at your IT provider) is doing what during a recovery. Reviewing this plan with all stakeholders is the first “dry run” of your drill. If you use a managed IT services provider (MSP) or backup vendor, involve them in the planning phase as well.
2. Start with a Tabletop Exercise (No Tech Needed). A tabletop exercise is essentially a brainstorming meeting where you walk through a hypothetical disaster scenario on paper. Gather your team and pose a scenario – say, “Our main server was hit by ransomware” or “A fire destroyed our server room”. Then discuss step-by-step how you would recover: e.g. “We’d switch to our cloud backup for files, restore the last server image to a spare machine or VM,” and so on. This low-impact drill often reveals gaps in your plan (maybe nobody knows the login to the backup system, or a key application isn’t covered in the plan). It’s a chance to update documentation and checklists without touching any live systems. Essentially, you’re verifying on paper that everyone knows their role and that the plan is complete.
3. Conduct a Small-Scale Backup Restore Test. Now it’s time to get hands-on, but you can start small. Choose a sample of data to restore as a test – for example, restore a few recently changed files or a folder to a different location, or spin up a backup copy of a single server in an isolated environment. The idea is to confirm your backup system can successfully retrieve data and that the data is intact. For instance, you might create a “test restore” folder on your network and use your backup software to restore last night’s files into it. Then compare those restored files with the originals – are they the same size, do they open correctly, do they contain the latest changes? This process ensures the backup data itself is sound and that you know how to perform the restore procedure. If you encounter any errors or missing data during this mini-drill, you can address them now (perhaps a particular file wasn’t being backed up, or the restore took far too long, etc.). Many backup administrators do this kind of spot-check monthly – sometimes called **“backup validation” – to catch problems early.
4. Use an Isolated Environment for Full-Scale Testing. To really be confident in your disaster recovery, you should occasionally test restoring an entire system (or multiple systems) as if a true disaster happened – but you obviously don’t want to take down your production while doing so. The solution is to perform the full restore in a safe, isolated environment. This could be a spare server, a virtual machine, or a cloud environment that’s not connected to your live network. For example, if you back up a server image, try restoring that image to a sandbox environment that mimics your production setup. With modern virtualization and cloud services, you can even automate this: some backup solutions can spin up virtual test machines to boot your backups and verify they run, then auto-delete them when done. Cloud DR drills are especially handy – you can temporarily restore systems into cloud infrastructure, test that everything works, and then shut it down when finished, with zero impact on your on-premises network. This way, you’re testing the full recovery process “for real” without handling live transactions or overwriting any current data. Be sure to note how long this process takes – did it meet your RTO? If not, you may need to adjust your strategy (for instance, maybe a different backup technology or sequence is needed to speed things up).
5. Simulate Different Disaster Scenarios Over Time. Don’t always test the exact same scenario. Your DR drills should, over the course of a year, touch on varied disaster scenarios to exercise different parts of your plan. One time, simulate a hardware failure (e.g. restoring a failed server from backup). Next time, simulate a cybersecurity incident like ransomware (e.g. test restoring clean data from an immutable backup). Another time, simulate a site-wide outage (power failure, fire, or natural disaster) – which is a good opportunity to test your off-site backups. For example, unplug your primary storage (in a test scenario) and try recovering solely from your off-site or cloud backups. Also, consider remote recovery: if your office is inaccessible, can you initiate the restore from home or a secondary location? Ensure you have access to needed credentials and that backups stored off-site can be reached and used remotely. Varying the scenarios helps you ensure there’s no single point of failure. It also tests your team’s readiness for different types of crises – whether it’s a server crash, a network outage, or a regional disaster. (Tip: Document a few likely scenarios in your DR plan and rotate through them in your drills. Over a year, you might do a ransomware recovery test in Q1, a database crash in Q2, a site-wide outage in Q3, etc.) The goal is to make sure your plan holds up to any type of disaster, not just one.
6. Document Results and Update Your Plan. After each drill, treat it as a learning experience. Document what happened: How long did each step take? Were there unexpected errors or challenges? Did everyone know what to do? What fixes or improvements were identified (for example, “backup X was missing some files – update backup job to include them,” or “need a better process to communicate status to management during DR,” etc.)? Keeping a record of test results isn’t just good practice for improvement – it can also help with compliance audits to prove you regularly test your backups. Most importantly, update your disaster recovery plan and checklists based on what you learned. If the drill revealed a gap, close it while it’s fresh. If it turns out your RTO of 4 hours wasn’t met (say it actually took 6 hours to restore everything), you might need to adjust either the plan or the expectation. Treat each test as a chance to refine and strengthen your DR capabilities. And finally, schedule the next drill! Make backup testing a recurring calendar event (at minimum annually, but more frequently if possible). This creates accountability and a culture of preparedness. As one industry expert put it, regular drills aren’t just routine busywork – they are critical evaluations that reveal weaknesses before a real crisis hits, driving strategic fixes and building overall resilience.
By following these steps, you can test even complex backup systems without endangering your live operations. The drills might require some after-hours or weekend time (many businesses schedule major recovery tests during off-peak times to avoid any interference), but consider that a small investment compared to the chaos of an untested recovery that fails when your business is on the line.
Best Practices for Ongoing Backup & DR Readiness
Performing a successful recovery drill is fantastic – but disaster recovery is not a “set it and forget it” task. Here are some best practices to keep your backups and recovery plan ready for the real thing at all times:
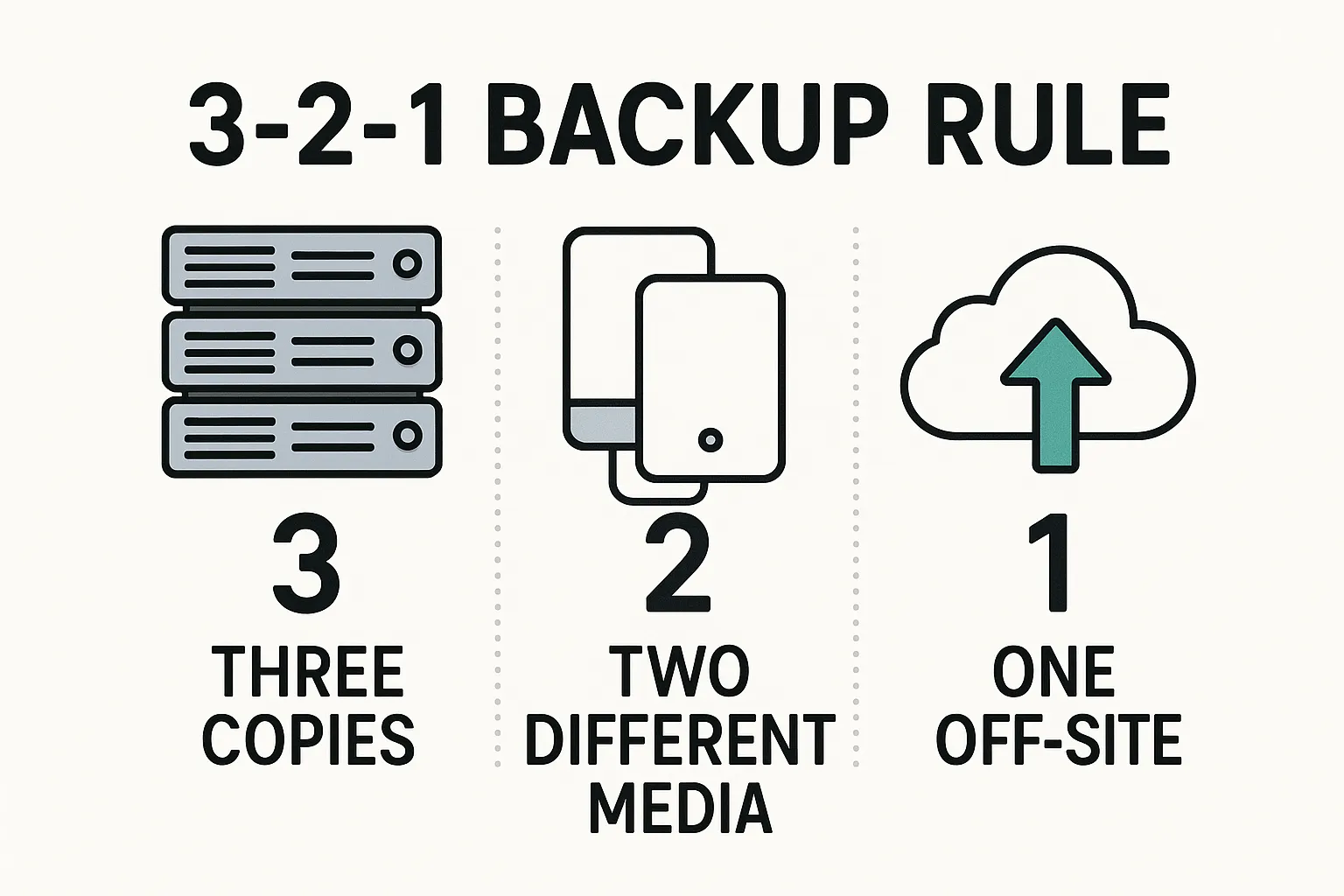
- Follow the 3-2-1 Backup Rule (and Beyond): This classic rule states you should keep 3 copies of your data (production + two backups) on 2 different media (e.g. cloud and external drive, or disk and tape) with 1 off-site copy. The idea is to prevent any single disaster from wiping out all copies. In fact, 90% of enterprises use the 3-2-1 strategy today. For example, you might have on-site nightly backups to a NAS device, plus automatic backups to a cloud service – that cloud copy covers you if the whole office is hit by fire or flood. In recent years, experts have suggested enhancing 3-2-1 to “3-2-2” for cyber-resilience – meaning one of the off-site copies is in an immutable storage (write-protected cloud archive) to defend against ransomware. The key takeaway: use multiple, redundant backups and always have at least one off-site. This gives you confidence that no matter the catastrophe (natural or cyber), some copy of your data survives for you to restore.
- Test Backups on a Schedule (At Least Annually): It’s easy to let testing slide when things get busy. Avoid that trap by scheduling regular drills or test restores. Aim for at least one full DR test per year as a minimum. Many businesses do two per year or even quarterly, especially if they experience a lot of changes in data or infrastructure. Critical systems or rapidly changing data might warrant even more frequent checks – for instance, some IT teams do monthly test restores of a sample of backups (not the whole system each time, but partial validations). The ConnectWise survey mentioned earlier found that most small businesses test far too infrequently – so if you commit to a schedule (and put it on the calendar with executive awareness), you’re ahead of the game. Remember, the more you test, the better prepared you’ll be.
- Automate Backup Monitoring and Verification: Leverage tools to help ensure your backups remain reliable. Most backup software can automatically report backup successes/failures – make sure someone is reviewing those alerts daily. Consider enabling features that do automated “health checks” or test restores of backups. For example, some modern backup solutions will automatically boot a backup VM in an isolated environment and verify it starts up correctly. These tools can catch backup issues early, without manual effort. Even simple scripts to periodically verify the integrity of backup files (e.g. checking archive logs or doing checksum comparisons) can add an extra layer of assurance. Automation reduces human error and helps maintain consistency in testing.
- Include All Key Systems and Data in Testing: Don’t focus only on files. Make sure you also test restoring applications and databases, and verify those come back online functional. For instance, if you have an accounting software or an EHR (Electronic Health Records) system for a clinic, a file-level restore isn’t enough – you need to be able to recover the application and its database and confirm users can log in and data is intact. Testing database backups is crucial, as databases might require consistency checks or special restore procedures. Similarly, test that server configurations, virtual machines, or cloud VM snapshots can be restored and run. Your disaster recovery drill should cover full-stack recovery, not just files on disk. Many an organization has discovered post-disaster that while their files were backed up, their critical applications wouldn’t launch properly on new hardware – often due to missing configuration backups or license keys. A thorough drill will catch those issues.
- Consider Disaster Scenarios in Your Region/Industry: Tailor some of your testing to the risks most relevant to you. For example, here in Missouri we occasionally face tornadoes and severe storms – so ensure you test the scenario of your office becoming unusable (requiring off-site recovery). If you’re a medical practice, simulate an outage to your patient records system and measure how quickly you can get it back (this also ties into compliance with HIPAA). If you’re a local government office, practice recovering from a power grid failure or a cyberattack on city servers. By aligning tests with realistic threats, you not only prepare technically, but you can also develop contingency workflows for how to operate during the outage (e.g. manual procedures while systems are down). Engage your whole team or department in these scenario-based drills so that both IT and end-users know what to expect in a real event.
- Keep Backup Copies Secure from Threats: Your disaster recovery readiness isn’t just about testing restores – it’s also about ensuring your backups survive potential threats. Modern cyber threats like ransomware target backup files too, trying to encrypt or delete them. Mitigate this by using immutable or air-gapped backups (offline or write-protected storage that malware can’t alter) for at least one of your backup copies. Also, protect backup systems with strong security (separate credentials, multi-factor authentication, network segmentation). During drills, you might include a step of verifying that your backup repository is safe and unharmed by whatever “disaster” you’re simulating. For example, in a ransomware scenario drill, confirm that your off-site backups were isolated from the hypothetical breach. A backup that’s been encrypted by ransomware is no backup at all, so part of testing is ensuring you have secure copies to draw from.
- Document and Train Continuously: Make disaster recovery drills part of your company culture. Keep improving your written DR plan documentation with each test – include detailed steps, contact lists, and lessons learned. New employees should be briefed on these procedures as part of onboarding if they will have a role in IT or data management. Consider cross-training team members so that there’s backup personnel for the backup process (no single IT person should hold all the recovery knowledge). Some businesses even create a “DR playbook” or checklist that lives in the cloud (or a printed copy in a safe place) so it’s accessible during an emergency. By having clear, updated instructions and well-trained people, you reduce panic and mistakes in a real crisis. As the ISACA experts note, consistent testing and refinement fosters a true culture of preparedness – your team will be ready and not just following a dusty script when something goes wrong.
Testing your backups and DR plan is not a one-time task – it’s an ongoing practice, much like regular maintenance on a vehicle. Each test builds confidence and uncovers ways to strengthen your defenses. When a real disaster strikes – whether it's a malware attack at midnight or a tornado cutting power – you'll have a well-oiled recovery process and a team that has been there, done that. Your business (or home) can get back on its feet with minimal damage.
Bottom line
Need help setting up or testing your disaster recovery plan?
Contact Pinpoint Tech for a free consultation to assess your backup systems and ensure your business is ready for anything.

FAQ: Disaster-Recovery Drills & Backup Testing
What is a disaster recovery drill?
How often should I test my backups and disaster recovery plan?
Aim to test at least once a year as a minimum for a full-scale disaster recovery drill. Many experts recommend more frequent testing – e.g. quarterly or semi-annually – especially for critical systems or rapidly changing data. Remember that over half of organizations currently test their DR plans only annually or not at all, which is risky. In practice, you might do smaller-scale backup restore tests more often (monthly brief tests of certain files or systems) and a comprehensive whole-plan drill annually. The more regularly you test, the more confident you can be. If any major changes occur (new infrastructure, major software updates, etc.), do a targeted test soon after those changes to ensure your plan still works.
How can I test my backups without disrupting my business?
What is the 3-2-1 backup rule everyone talks about?
The 3-2-1 backup rule is a widely recommended strategy to ensure data resiliency. It means having 3 copies of your data, on 2 different types of storage media, with at least 1 copy stored off-site. For example, you might keep a primary copy on your server, a second copy on a local backup drive, and a third copy in a cloud backup service or at a remote location. This way, no single event (like a hardware failure, site fire, or even a ransomware attack) will wipe out all your data. Even if one backup fails, you have others. Many businesses follow this rule – in fact, about 90% of enterprises use 3-2-1 in some form. The “off-site” part is critical: it protects you if your whole building or network is hit by something. Today, off-site often means cloud backups due to their convenience and geographic separation. In some cases, people extend the rule (3-2-2, etc.) to add additional safeguards like an extra off-site copy or immutable storage, but 3-2-1 is the foundational guideline for robust backup setup.
What should I do if a backup restore test fails?
If your disaster recovery drill reveals that a backup is unrecoverable or something doesn’t work, don’t panic – be glad you found out during a test, not during a real emergency! First, diagnose the issue: Was the backup file itself corrupted or incomplete? Did the restore process encounter an error (and if so, what kind)? Or was the data restored but the system didn’t run correctly (indicating maybe additional components/configurations were missing)? Once you identify the problem, take corrective action immediately. This could mean fixing your backup jobs (ensuring all necessary files and systems are included going forward), switching to a more reliable backup method, or updating your procedures. For example, if a backup of a database failed to restore properly, you might need to adjust how you back up that database (maybe use a different backup mode or include log files). After fixing the issue, run a new test to confirm the backup is now restorable. It’s also wise to keep multiple backup versions – if the most recent backup is bad, an earlier one might still work. Finally, analyze why the failure happened to prevent it in the future (perhaps add an automated backup verification step). The silver lining is that a failed test is a learning opportunity: it lets you strengthen your backup strategy so that if a real disaster strikes, you won’t be caught off guard by the same failure.
Sources
- ConnectWise – How often should you test your disaster recovery plan?
https://www.connectwise.com/blog/how-often-should-you-test-your-disaster-recovery-plan
- ISACA – Ensuring Data Security: The Importance of Cloud Backups and Drill Testing
- SBS CyberSecurity – IT Disaster Recovery Testing Best Practices
https://sbscyber.com/blog/how-to-mature-your-disaster-recovery-testing-plan
- Wingman Solutions – Backup Restore Test: How To Test Your Backups
- Trilio – Are You Testing Your Backups for Recoverability?
- Ask Leo! – Testing Your Backups Is Critical
- Backblaze – Is Your Data Really Safe? How to Test Your Backups
- HPE Community Forum – Testing backups – best practice
https://community.hpe.com/t5/servers-general/testing-backups-best-practice